My name is Anh Thu, I am currently preparing a bachelor degree in data sciences at CY Tech (Ex EISTI). I am actively looking for a five months internship in Data Science starting from April to September 2023 with the possibility of extending it to an apprenticeship.
1. Text Classification for Restaurant Reviews using Machine Learning models:
-
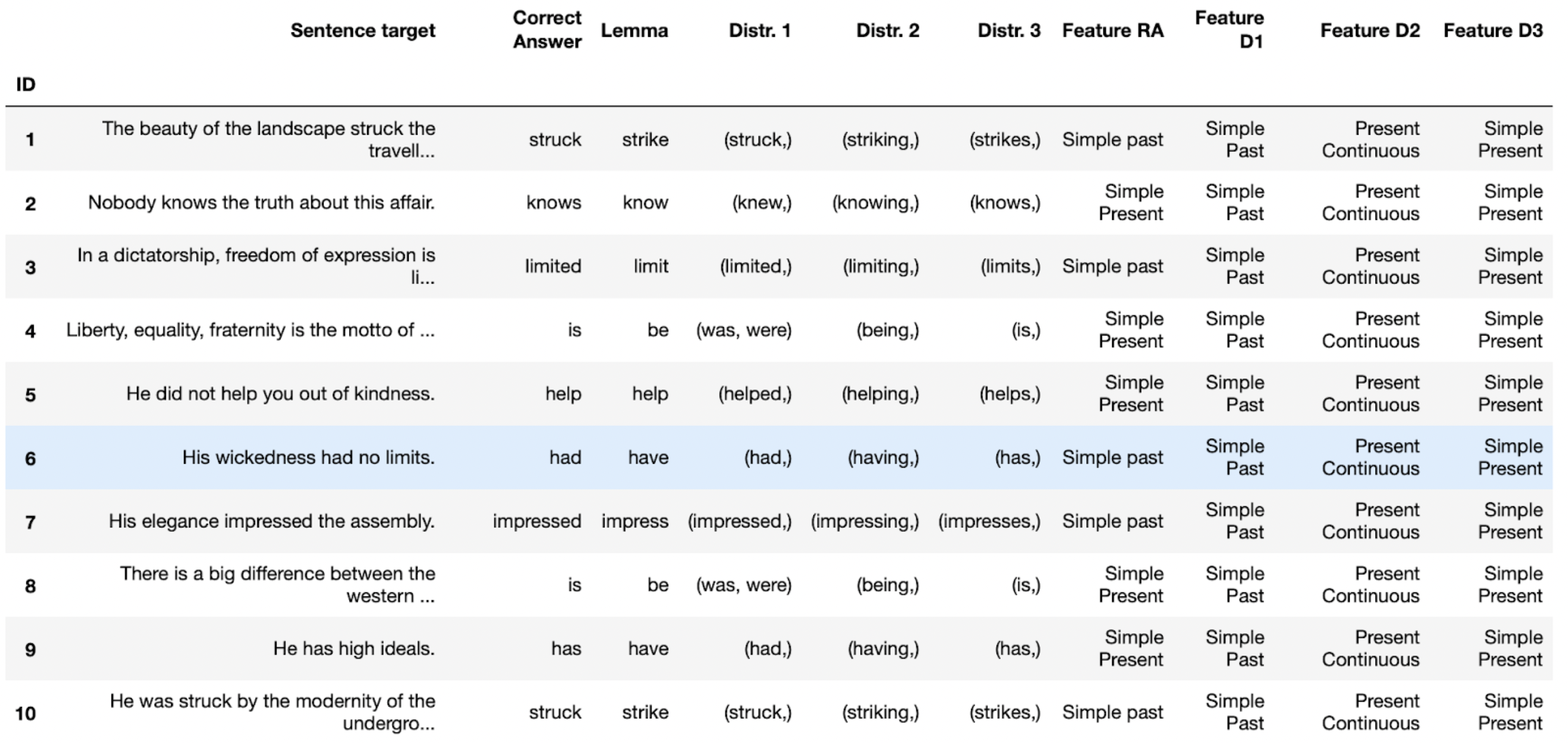
The data we used in this project were annotated two times by two differents annotators, calculated the percentage of misannotated reviews led to a difference in the annotations between the annotators.
-
Used sentiment analysis on the rows with annotation disagreement.
-
Chose the baseline classifier based on the most-frequent class in the training dataset.
-
Created machine pipeline to evaluate the performance of several models and tuned hyperparameter on the highest accuracy model (SVC & LSVC)

-
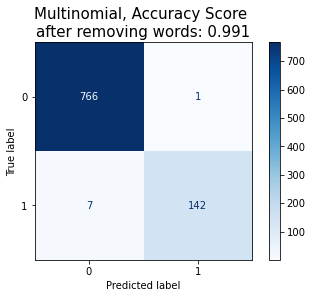
Evaluated the model (with model’s accuracy, confusion matrix, precision and recall table)


-
Identify the top 20 features contributing to LinearSVC classification performance to distinguish whether a review was negative or positive.

2. Credict Card Fraud Detection
-
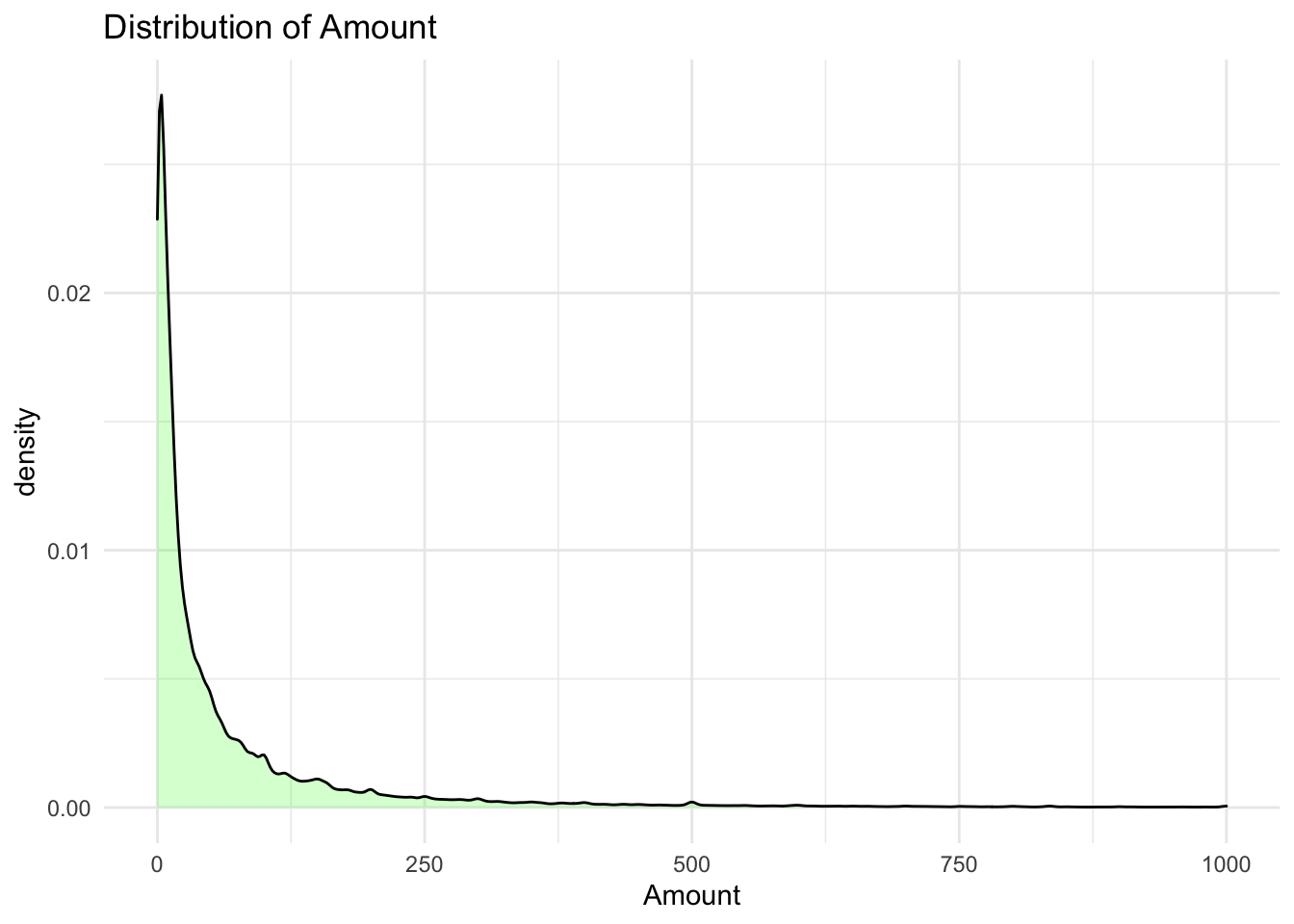
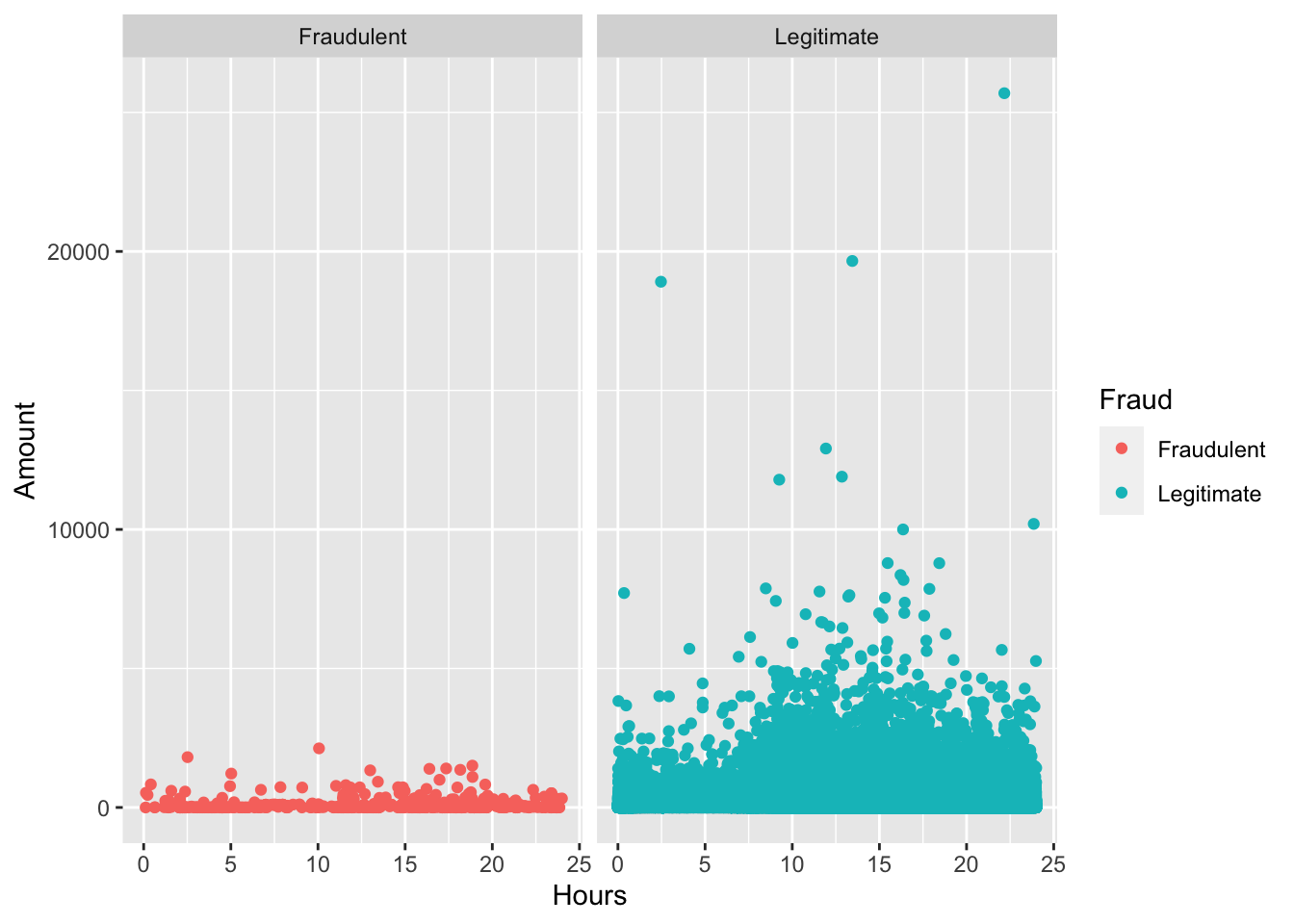
The data was collected from over 285,000 anonymized transactions made by credit cards in September 2013 by European cardholders
-
Explored the interactions and correlations between features then visualize them.
-
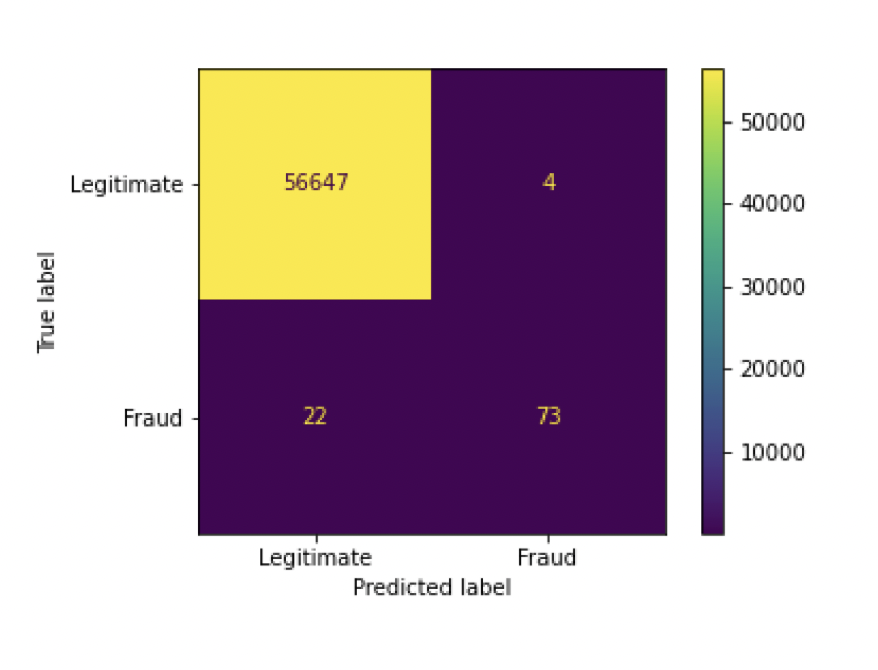
Used Pipeline and GridearchCV to find the best hyperparameters for different models.
-
Evaluted the best model as result.
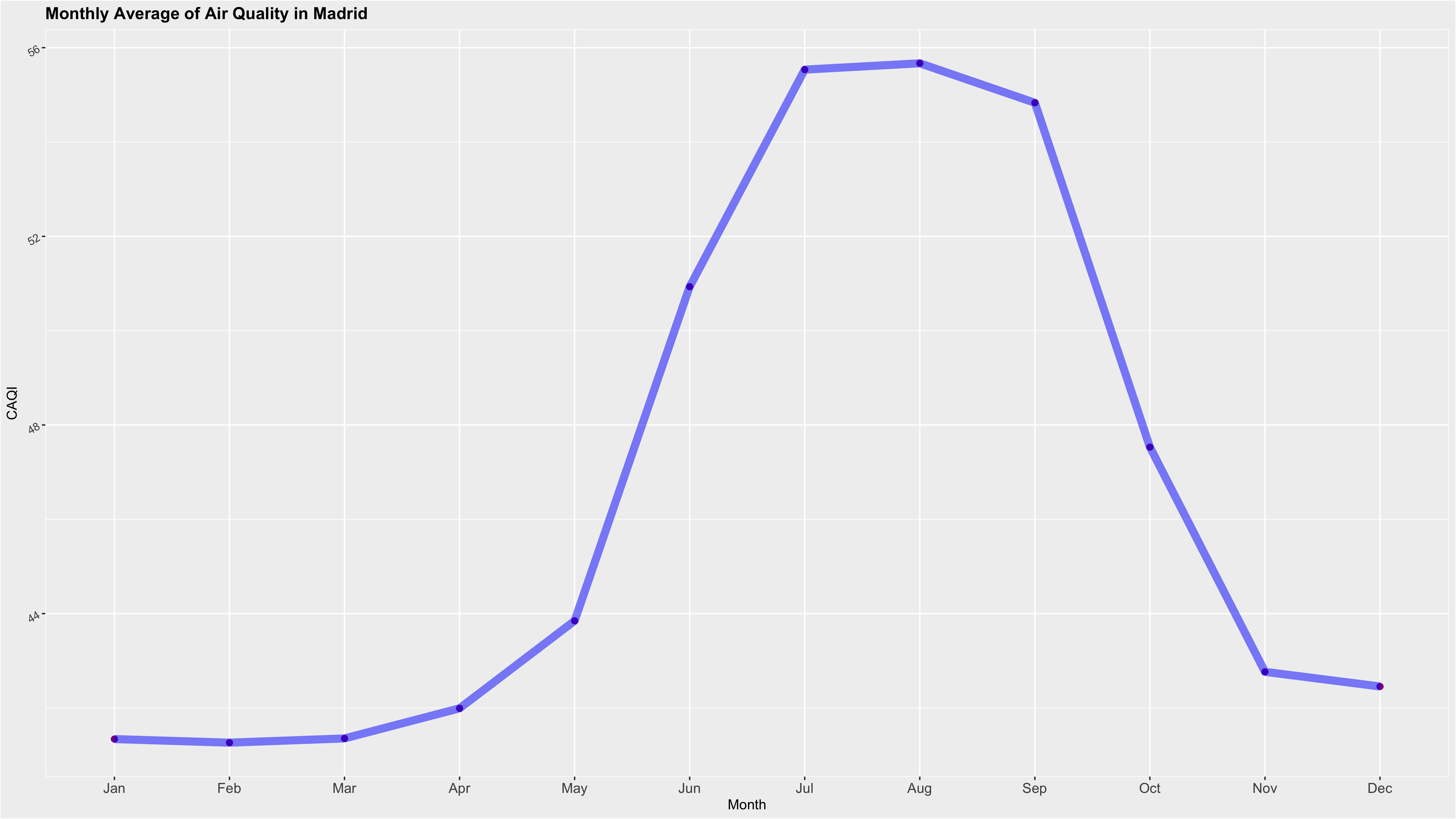
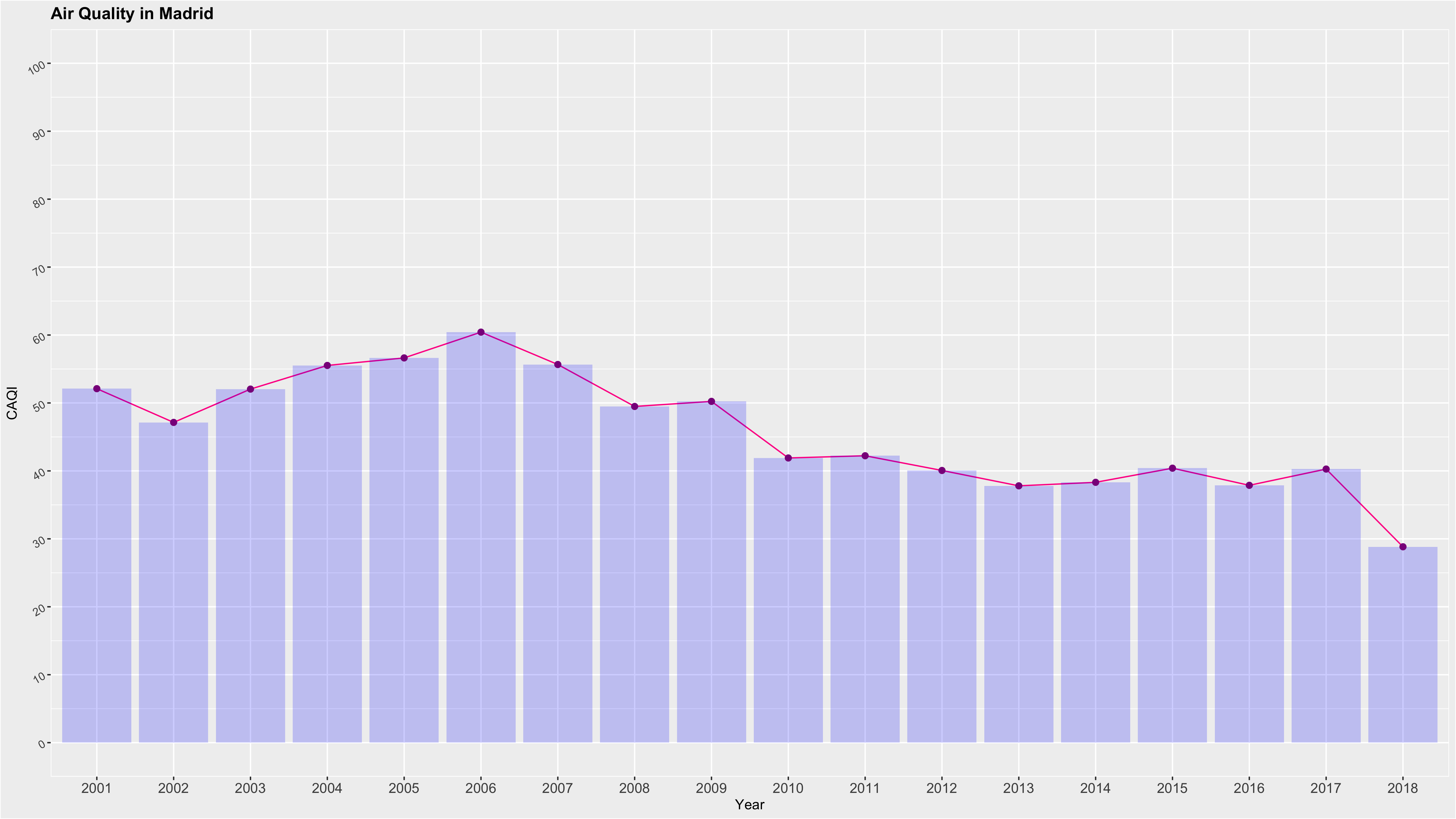
3. Madrid’s Air Quality Analysis & Forecasting
-
This dataset is created in the Madrid’s City Council Open Data website. It contains in a practical format 18 years (2001-2018) of daily and hourly data.
-
Reformatted the structure of the dataset using forecast, tidyverse, ggplot2, and xts libraries from R
-
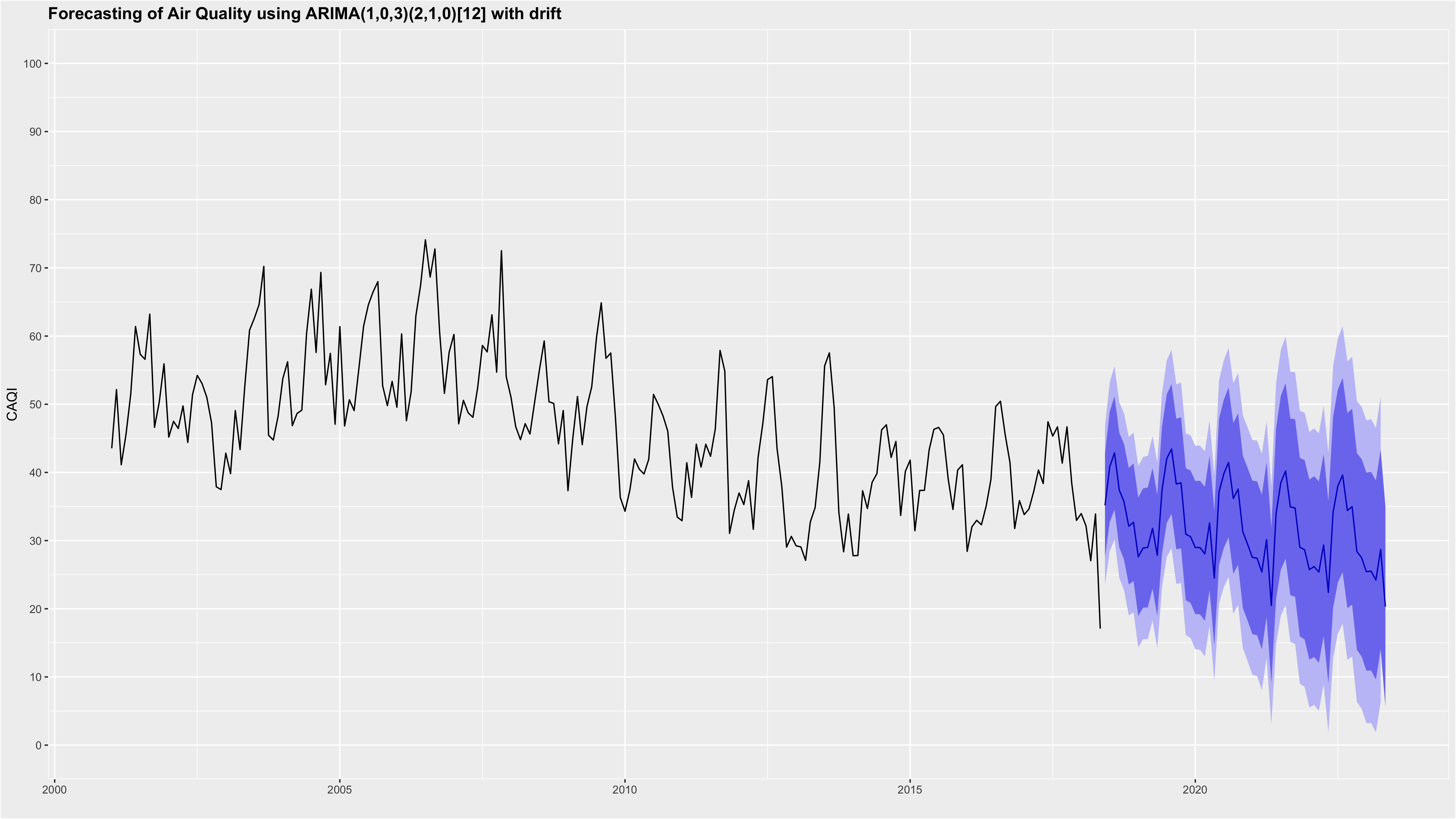
Choice of the variables (Particles smaller than ten μm (PM10), Ground-level Ozone (O3), Nitrogen dioxide (NO2)) which are core pollutants based on airqualitynow.eu
-
Used the function auto.arima from the forecast library to generate our prediction model, the output returns an ARIMA model with the best set of hyperparameters to fit the data.
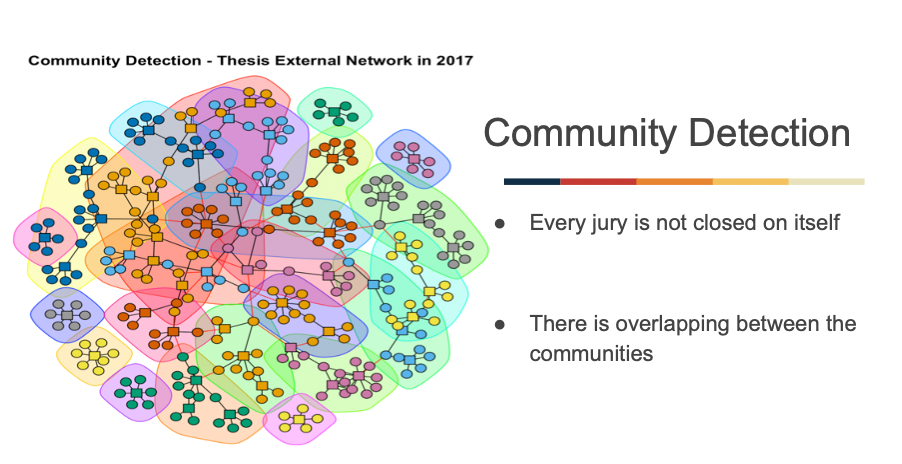
4. Social Network Analysis of the juries of Maître de Conferences (MCF)
-
The data is constituted of each member of the jure of Maître de Conferences (MCF) from 2017 to 2020.
-
To understand a community by mapping the relationships that connect them as a network and then drawing out key individuals, groups, or associations between the individuals.


5. Clustering the phi and psi angle combinations in protein
-
The distribution of phi and psi combinations.
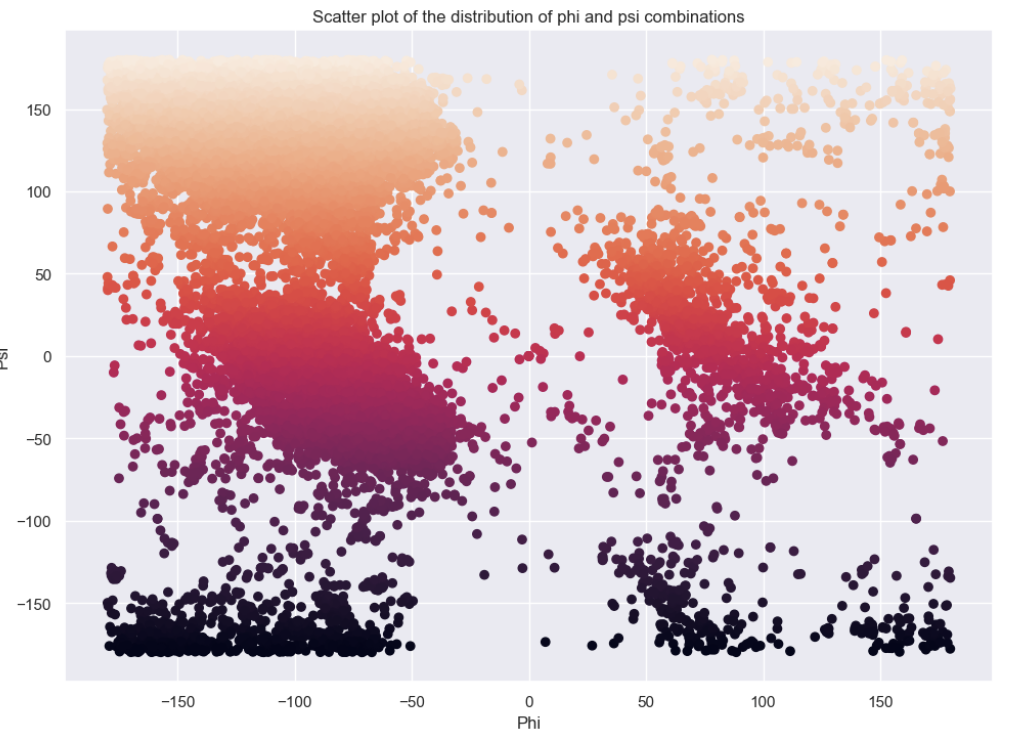
-
Used the K-means clustering method to cluster the phi and psi angle combinations with the value of k is based on the histogram of the distribution and by using elbow method.
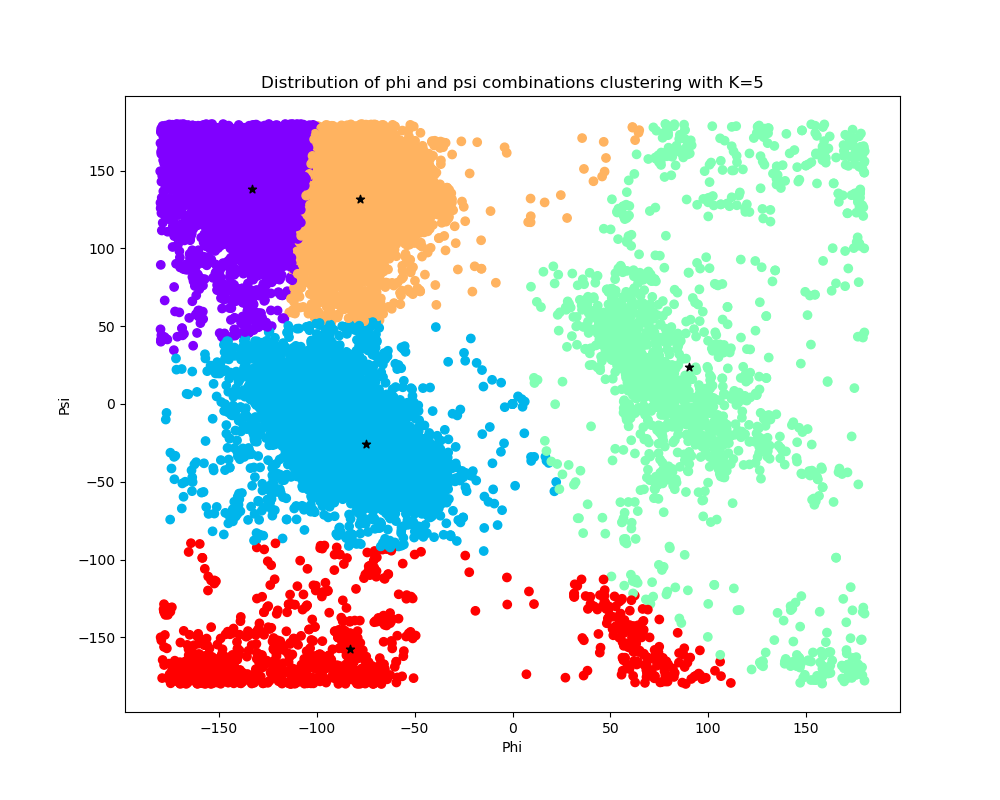
-
Because of the periodic attributes of phi and psi, we shifted the data for better clustering.
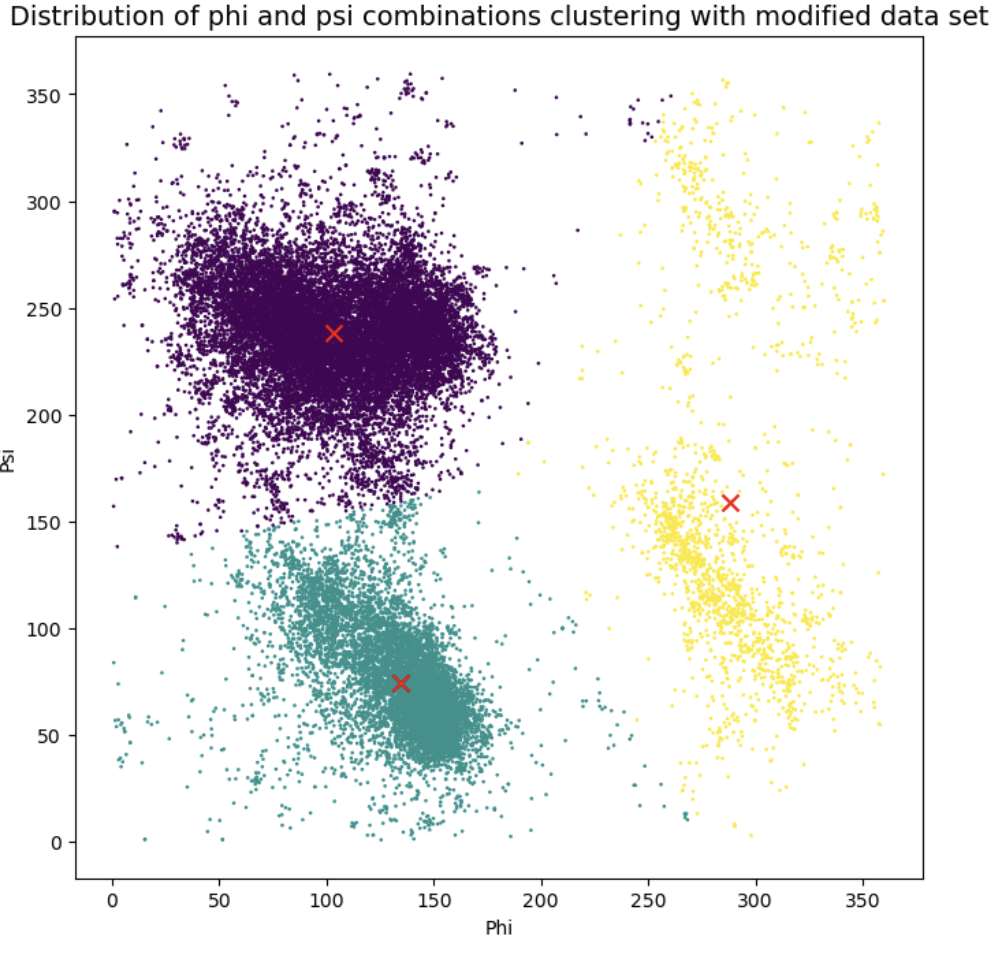
-
Compare the clusters found by DBSCAN with those found using K-means.
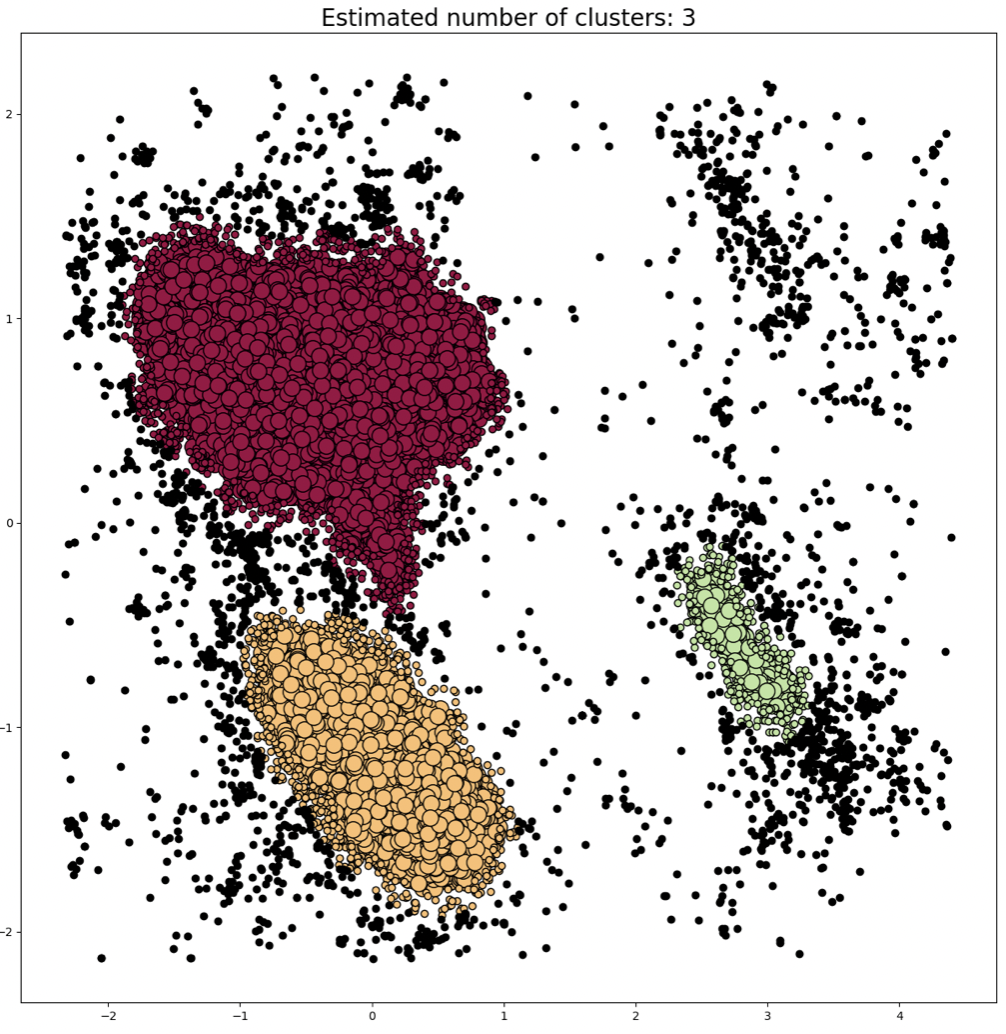
6. Email spam classification using Naive Bayes
- The main purpose of this project is to implement a Na ̈ıve Bayes classifier that will classify emails into spam and non-spam (“ham”) classes. Na ̈ıve Bayes Classifier is one of the simplest and most efficient classification algorithms that helps to build fast predictive speed machine learning models. It is a probabilistic classifier, which means it predicts on the basis of the probability of an object.
7. Dimensionality Reduction & Clustering techniques on Dating app’s data.
-
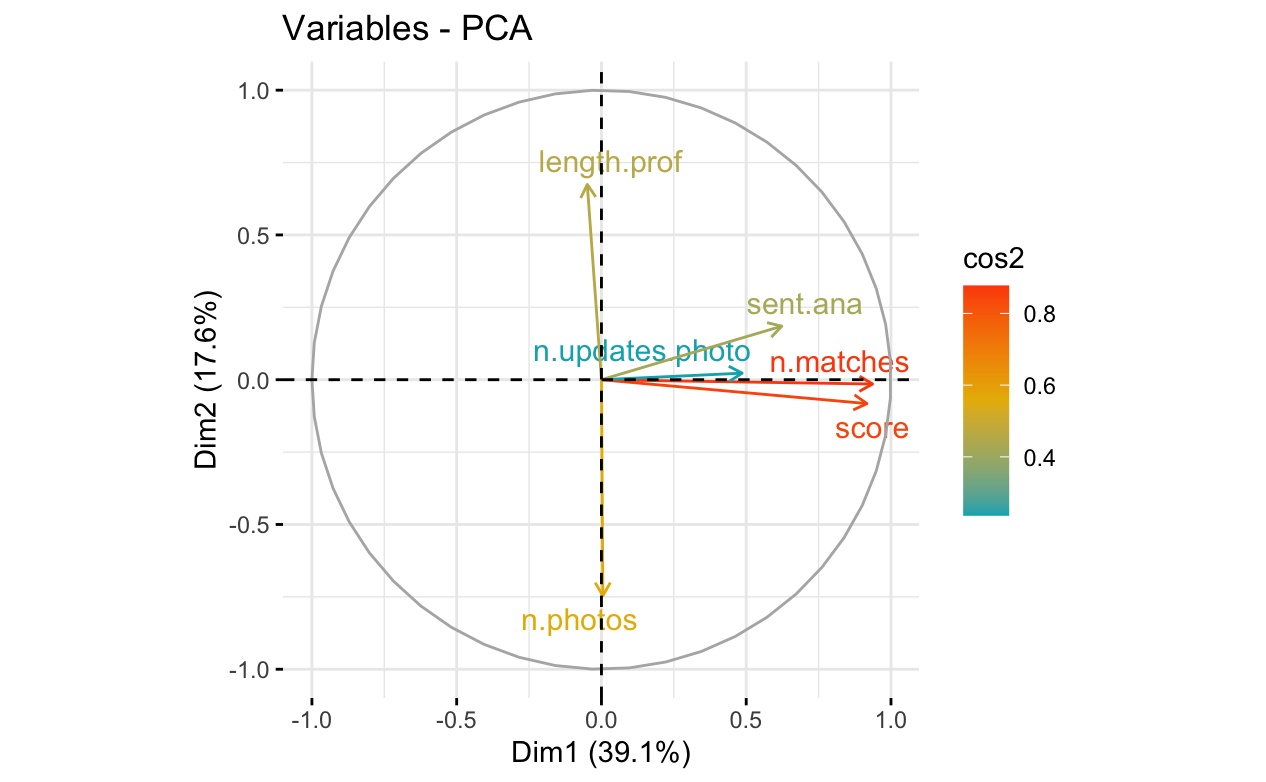
Performed a PCA on relevant continuous variables of the dataset
-
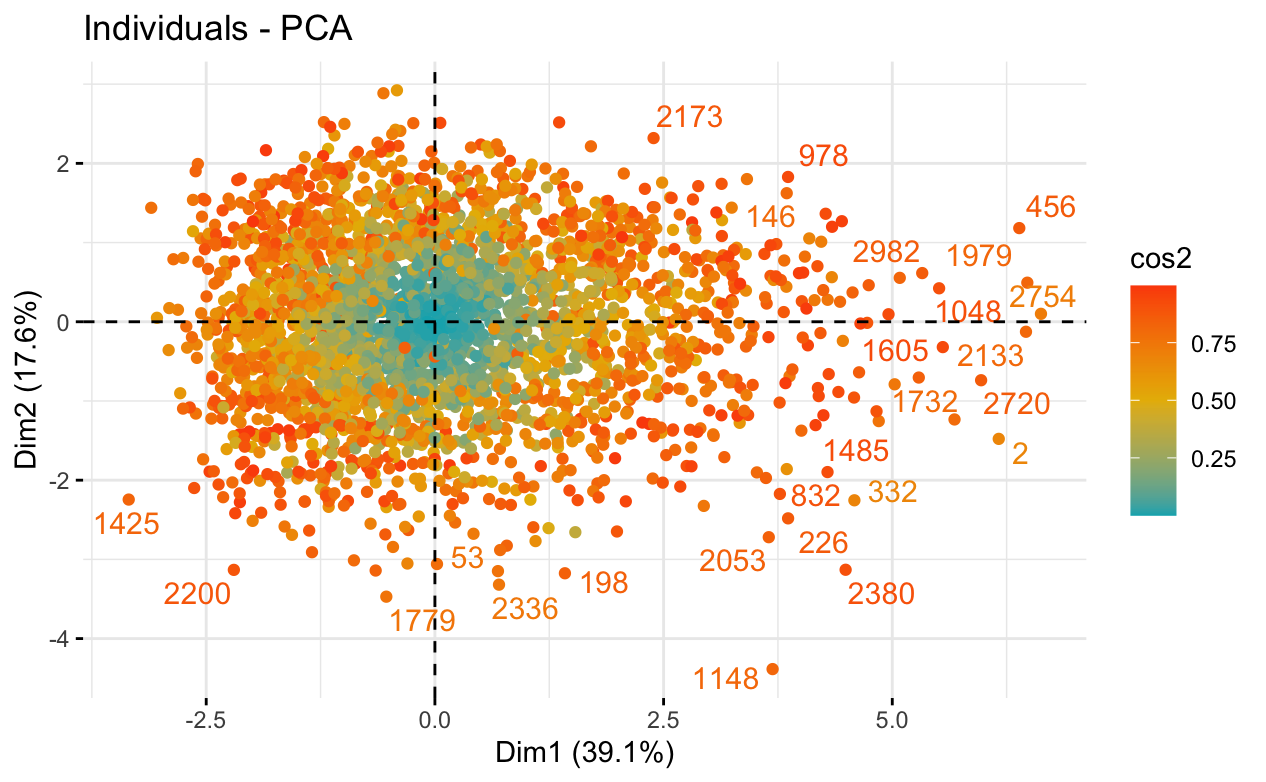
Created an individual map with a sample of individuals.
-
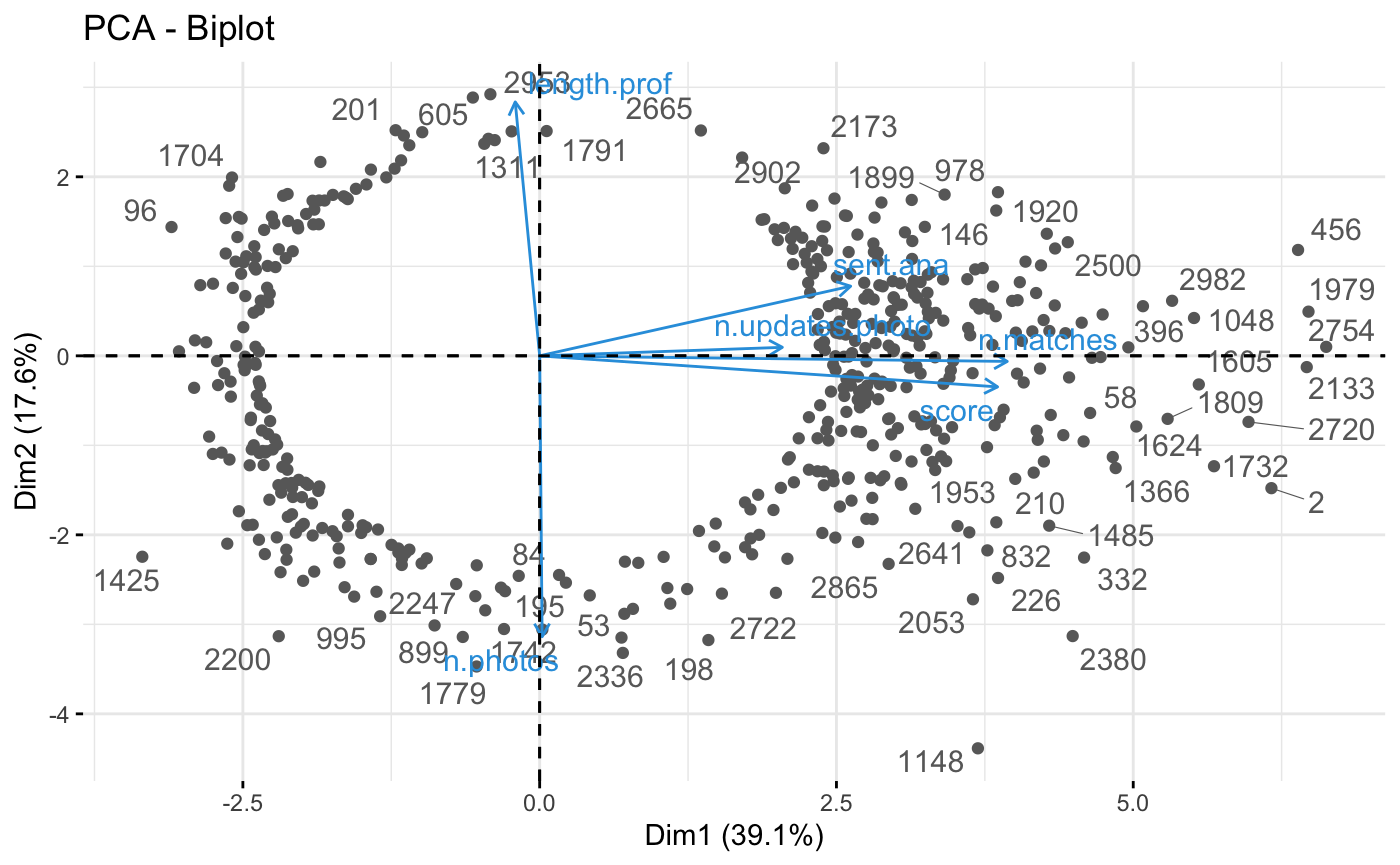
Created a biplot with a limited number of individuals.
-
Performed a MCA on relevant discrete variables of the dataset.
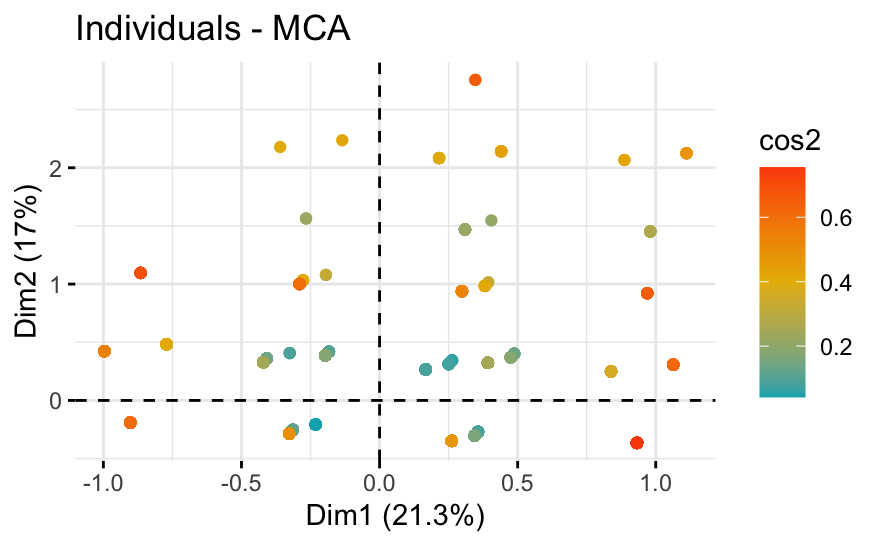
-
Perform a k-means clustering on principal components of the analysis.
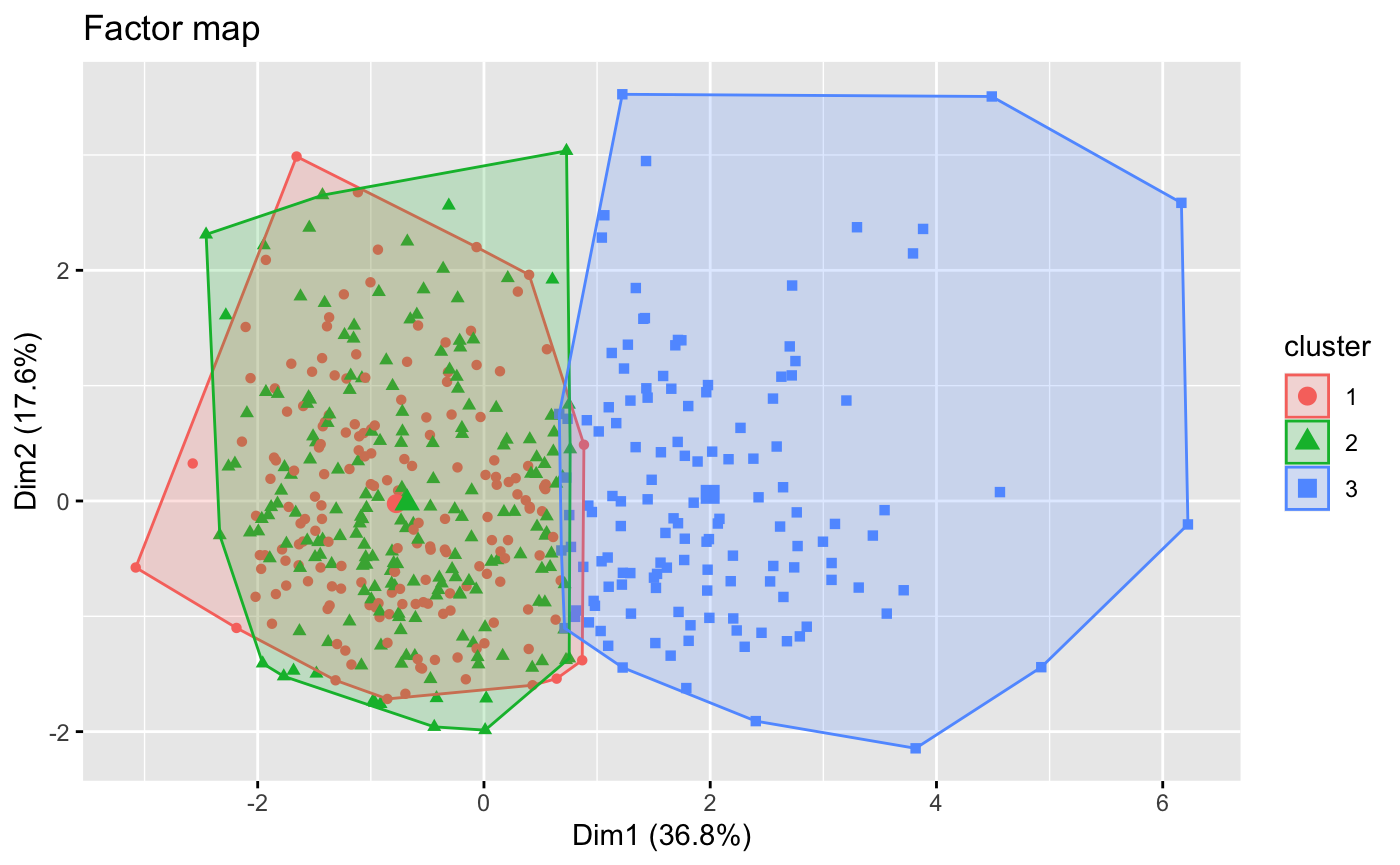
-
Perform and HCPC on continuous variables.
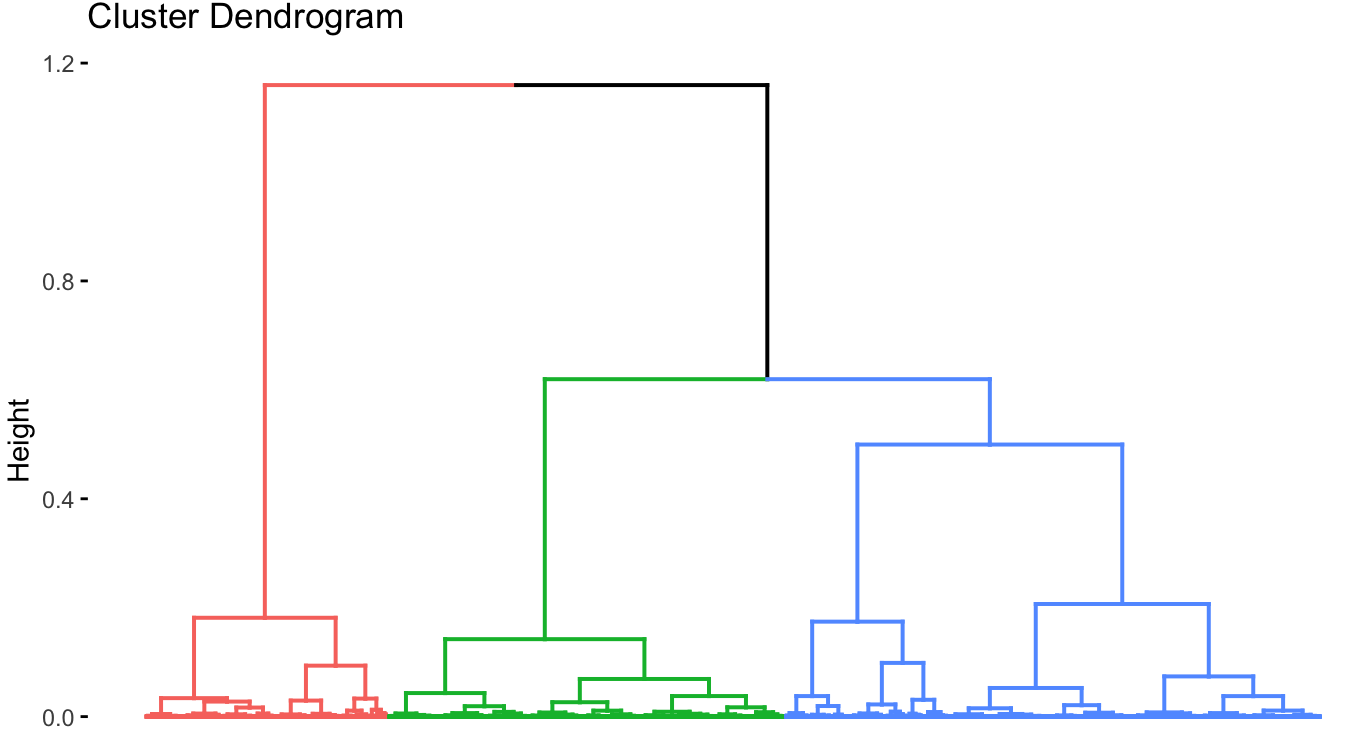
8. Text Mining and Natural Language Processing on French doctoral dissertations
- Detected the language of the document using stop words.
- Used TF-IDF and cosine to assess similarity between thedocument.

- Trained and used a bigram and a n-gram model on a relevant part of the dataset.
- Applied a conjugator-based strategy to the sentence corpus and propose a relevant automatically generated exercise based on this tool by using spaCy and stanza libraries.